
Written by Dr Shalen Sehgal | Crises Control
The pressure sensor fired at 3:14 AM. The alert reached six devices. Nobody moved for eleven minutes.
That gap between the moment a system detects a problem and the moment a trained person takes the first accountable action is where oil and gas incidents become disasters. Not the detection. The eleven minutes.
The crisis management software industry has spent two decades optimising the wrong half of that sentence. Faster alerts. More channels. Higher delivery rates. Better dashboards. Every metric points at the moment the notification leaves the system. Almost none of them measure what happens next: whether the right person received it, understood what was expected of them, confirmed they were acting, and completed the task in the sequence the response plan required.
In a gas plant at 3 AM, with a pressure sensor triggering and a supervisor trying to reach a shift team across three locations, the alert is the beginning of the problem, not the solution to it. The response is what trained people do, in the right order, with clear ownership, under pressure. Most platforms have been engineered for the first three seconds of an emergency. The industry’s worst incidents were decided in the eleven minutes that followed.
Crisis management software has to tell everyone what to do next, assign who does it, track that it happened, and prove it afterwards. An alert tells you something is wrong. That is a different product category entirely.
The Notification-to-Action Gap: Why Oil and Gas Operations Need More Than Alerts
Call it the notification-to-action gap. It is the window between an alert being received and accountable, coordinated action beginning. In a remote offshore environment, on a pipeline corridor spanning multiple states, or across a refinery where three contractors are working simultaneously, that window can be fifteen seconds or fifteen minutes. The difference between those two figures is a function of your systems, not your intentions.
That gap has consequences the industry can measure. According to the Pipeline and Hazardous Materials Safety Administration, pipeline incidents in the United States have averaged 1.7 per day since 2010 1.69 per day in 2023 alone. The International Association of Oil and Gas Producers reported 32 fatalities across 21 separate incidents in 2024, with explosions, fires, and burns accounting for 41 percent of those deaths.
These numbers are not evidence of an industry that fails to detect problems. They are evidence of an industry where the interval between detection and coordinated action remains dangerously wide.
Individual offshore platforms can lose over $1 million per day during an unplanned shutdown, according to industry estimates. A 2016 Kimberlite study found offshore operators average $38 million annually in unplanned downtime costs, with the worst performers exceeding $88 million. The width of your notification-to-action gap directly determines where in that range you sit.
No incident makes this clearer than the Deepwater Horizon explosion on 20 April 2010. Eleven workers died when a blowout on BP’s Macondo Prospect well caused the drilling rig to explode and sink. Before the well was capped on 19 September 2010, approximately 4.9 million barrels of crude oil had entered the Gulf of Mexico – the largest marine oil spill in the history of the petroleum industry. A 2016 court settlement for natural resource damages alone reached $8.8 billion.
Post-incident investigations identified poor risk management, failure to observe critical indicators, inadequate well control response, and insufficient emergency response training as central causes. The alert had not failed. The mechanism for turning detection into coordinated, documented action had.
The right crisis management software closes that gap. Here are the seven features that determine whether your platform can actually do it. For broader context on why generic platforms fall short in this sector, see our guide to crisis management software for oil and gas operations.
Feature 1: Multi-Channel Mass Notification That Reaches People, Not Inboxes
When an incident begins on an offshore platform or a remote pipeline site, no one is at a workstation. The first requirement of any crisis management software is the ability to reach people through multiple simultaneous channels – SMS, voice call, push notification, email, and desktop alert – not sequentially, but at the same time. The PING mass notification system sends across all five channels simultaneously, ensuring no single point of channel failure can delay the alert.
SMS matters more than most vendor presentations acknowledge. Push notifications fail when apps have not been updated or when phones are set to battery-saving mode. Email is inaccessible to workers wearing PPE in confined spaces. SMS reaches almost any device on almost any network, including roaming, which is often the only connectivity available on remote sites.
The practical standard: if your notification system relies on a single channel, it will fail the first time conditions prevent that channel from working. In oil and gas, those conditions are common enough that they are not edge cases – they are shift conditions.
Notification delivery must also be trackable. Knowing who has received an alert and who has not acknowledged it is the operational data that allows an incident commander to identify communication gaps and escalate manually where needed. Delivery rates tell you the system worked. Acknowledgement data tells you the response is moving.
Feature 2: Role-Based Task Assignment, Not Name-Based
Shift patterns in oil and gas operations mean the person named in your emergency response plan may not be the person on site when an incident occurs. If your platform assigns response tasks to named individuals, your entire emergency response depends on contact data being perfectly current at every moment. It never is.
Role-based task assignment solves this at the system level. When an incident is triggered, tasks go to whoever holds a given role on the current shift. There is no manual checking of rosters. No phone calls to find out who has just handed over. No gaps because someone went on leave and the plan was not updated. Incident response automation means the workflow runs the moment the incident is declared, regardless of who is available to run it.
When a pipeline integrity event occurs at 11 PM and the primary contact is mid-flight, the response does not stall waiting for someone to manually identify a backup. The software already knows. The task is already assigned. The next step is already underway.
Investigations into emergency response failures across high-hazard industries consistently identify handover failures and roster gaps as proximate causes of delayed action. Role-based assignment removes an entire category of failure from your emergency response architecture.
The platform should also allow two-way communication so that role holders can confirm their status, report their location, or flag that they need support. A system that broadcasts instructions without receiving field confirmation is still a one-directional notification tool, not a response platform.
Feature 3: Geo-Targeted Alerting to Preserve Alert Urgency
A gas leak at one facility should not generate a full emergency notification for every team across your entire operation. Alert fatigue is a well-documented safety problem in high-hazard industries. When workers receive alerts that consistently do not apply to their location or role, they begin to treat all alerts as lower urgency. In an industry where the first five minutes of an incident determine the trajectory of the response, that trained inattention is a safety failure.
Geo-targeting solves this by sending alerts only to teams in the affected area, contractors on the relevant site, and supporting functions whose role is specifically triggered by that type of incident. Everyone else receives no alert – or, where relevant, a situational awareness update rather than an action notification.
This requires your platform to carry accurate location and site data and to allow you to configure incident types against geographic zones and team structures. The configuration effort is a one-time investment that pays dividends on every activation thereafter.
When people receive too many notifications that do not apply to them, they stop treating alerts as urgent. Geo-targeting does not prevent incidents – it ensures that every alert that does fire is treated as the emergency it is.
Feature 4: Automated, Time-Stamped Audit Trails
Under OSHA’s Process Safety Management standard (29 CFR 1910.119), covered facilities must maintain emergency action plans, conduct compliance audits at least every three years, and document their response to audit findings. The EPA’s Risk Management Program adds a parallel layer of documentation requirements. In the event of a serious incident, regulators and investigators will want to know precisely what happened, in what sequence, and who held responsibility at each step.
Manual documentation during an active incident is not reliable. Under real emergency conditions, people act. Recording what they did accurately and in the right sequence is secondary. This is not a criticism of operators – it is a description of how human attention works under pressure.
The right crisis management platform creates its audit trail automatically. Every alert sent, every task assigned, every acknowledgement received, every escalation triggered – all logged with a timestamp without anyone having to create that record. Crisis management workflows build this record without adding to the response team’s workload. By the time an incident closes, the compliance documentation exists – not as a post-incident burden, but as a natural output of using the platform.
For operations subject to BSEE oversight, API standards, or regional regulatory frameworks outside the United States, the same principle applies. The documentation regulators require after an incident is the same documentation that tells your own teams what worked, what was delayed, and where the process needs improvement.
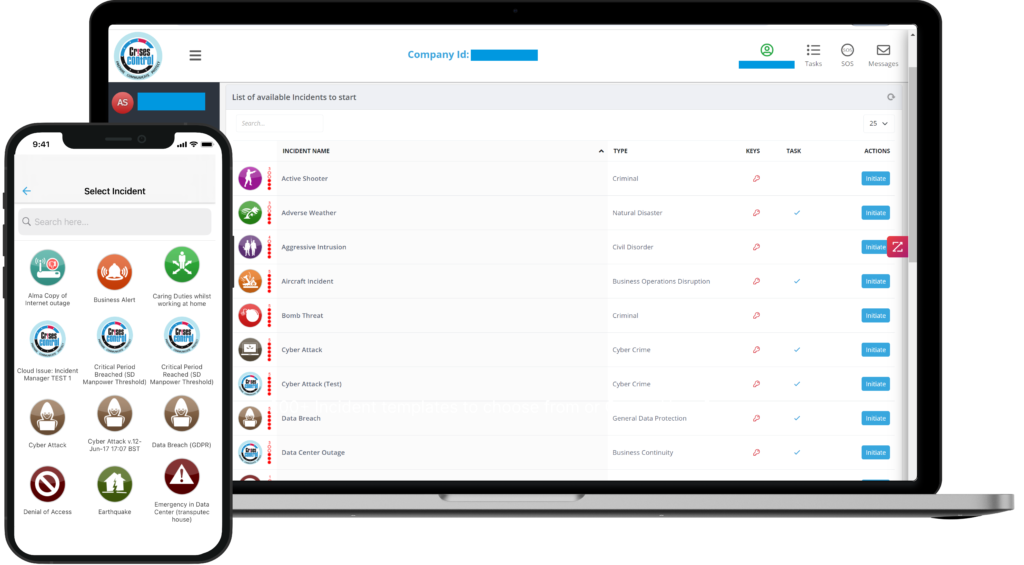
Interested in our Incident Management Software?
Flexible Incident Management Software to keep you connected and in control.
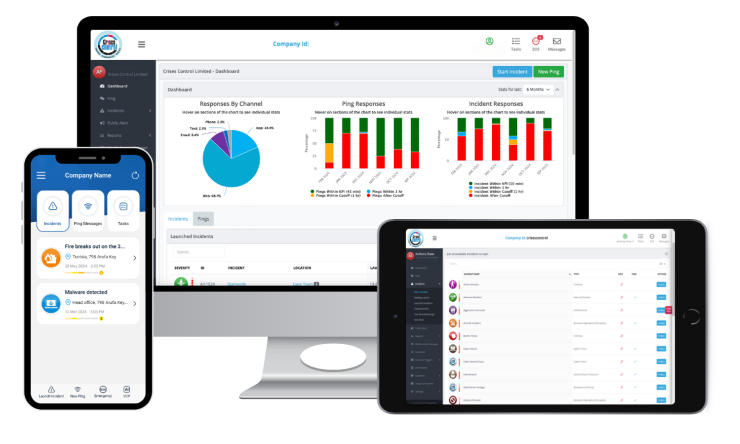
Feature 5: Live Incident Dashboard for Decision-Makers
During an active emergency, the people making consequential decisions – whether to escalate, whether to expand an evacuation zone, whether to call in external emergency services – are operating without complete information. In organisations without a centralised incident view, those decisions are made on the basis of fragmented reports, phone calls, and incomplete situational awareness.
A live incident dashboard changes the information available to decision-makers in real time. It shows which tasks have been completed, which are in progress, and which have not been acknowledged. It shows where teams are and what they are reporting. It shows whether the response is moving at the pace the incident requires or whether something is stalled.
Oil and gas emergencies rarely stay contained to a single dimension. A fire at a processing facility can simultaneously trigger worker evacuation, equipment shutdown procedures, environmental containment protocols, contractor notifications, and regulator communications. Without a live operational view, the incident commander manages each stream separately, through separate conversations, with no single source of truth.
The dashboard should not require a desktop environment. Field supervisors and emergency leads need to access the same operational view on a mobile device, on site, while the incident is active. Guesswork has no place in an emergency.
Feature 6: Resilient Infrastructure Independent of Your Primary Systems
Oil and gas incidents frequently compromise the systems that would ordinarily be used to manage them. A cyberattack affects your network. An explosion damages on-site communications infrastructure. A major weather event takes down local connectivity. In each case, the emergency response system needs to keep working after the primary environment has been affected.
Crisis management software for oil and gas should operate on its own cloud infrastructure, entirely separate from your primary IT systems. If your main network goes down, your crisis response platform stays up. That independence is not a theoretical resilience benefit – it is a foundational requirement for any environment where the incident itself might be the thing that takes your normal systems offline.
When Aramco was hit by the Shamoon cyberattack in August 2012, approximately 30,000 workstations were rendered inoperable, forcing coordination by phone and fax. Colonial Pipeline’s response to the May 2021 DarkSide ransomware attack was hampered because the IT infrastructure for communication and coordination shared dependencies with the compromised systems. Crisis management software that runs independently of corporate infrastructure remains operational precisely when the rest does not.
For operators with assets in multiple regions, the platform should also have data centre coverage across relevant geographies, including any specific data sovereignty or local hosting requirements. Operations across the Middle East, North America, Europe, and the Asia-Pacific face regional requirements that are not optional from a regulatory standpoint.
Feature 7: Integration With SCADA and Existing Operational Systems
Crisis management software that operates in isolation from your existing operational technology is a second system that people have to remember to use. In practice, response platforms that require manual incident logging from SCADA alerts, or that cannot pull location data from HR systems, become parallel processes that compete with the tools people already know. Under pressure, people default to familiarity.
The right platform integrates with the systems already in place: SCADA and process monitoring systems that can trigger automated incident notifications, HR directories and Active Directory services that keep role and roster data current, emergency communication tools already in use by coordination teams, and any environmental monitoring or pipeline management systems relevant to your operational context.
Integration does not mean replacing your operational technology stack. It means your crisis response platform becomes the layer that connects existing data sources and activates response workflows when conditions cross defined thresholds. The alert from SCADA becomes the trigger. The platform handles what happens next.
For operators running multiple assets across different infrastructure generations, integration capability is also a longevity question. A platform that integrates cleanly now can absorb new operational systems as they are introduced, rather than becoming a siloed tool that requires manual bridging every time the operational environment changes.
Closing the Gap Before the Next Incident
The IOGP has been collecting safety incident data from member companies since 1985. The fatal accident rate in 2024 – 0.77 per 100 million hours worked – is more than 90 percent lower than the rate recorded at the start of that period. The industry has made genuine, sustained progress on safety.
But the IOGP’s 2024 data also shows that explosions, fires, and burns remain the leading cause of fatalities, accounting for 41 percent of deaths across five incidents in that year alone. The incidents are happening. The question is whether your response architecture is built to close the notification-to-action gap before those incidents escalate.
Every feature in this list answers the same underlying problem: the moment between a crisis being detected and a coordinated response beginning. Multi-channel notification reaches people wherever they are. Role-based assignment ensures someone owns every action. Geo-targeting preserves the urgency that makes alerts actionable. Automated audit trails make compliance a natural output rather than an additional burden. Live dashboards give decision-makers the situational awareness to act rather than react. Resilient infrastructure keeps response systems running when primary systems fail. Integration with SCADA and existing tools ensures the platform is used, not bypassed.
Software does not make decisions. People do. But the right platform gives people the structure, information, and accountability to make the right decisions in the first minutes that matter most.
How Crises Control Supports Oil and Gas Operations
Crises Control is a crisis management platform built for high-risk, distributed operations. In oil and gas environments, it delivers multi-channel mass notification via SMS, voice, push, email, and Microsoft Teams simultaneously, with delivery and acknowledgement tracking on every alert sent. Task assignment is role-based, with automated escalation when tasks are not acknowledged within defined timeframes. Every action is automatically logged and time-stamped, creating a compliance-ready audit trail without additional administrative effort from response teams.
The platform operates on its own cloud infrastructure with data centre coverage across the UK, Europe, North America, and the Middle East, including local hosting in Saudi Arabia for operations with regional data sovereignty requirements. It integrates with SCADA systems, HR directories, Microsoft Teams, and Active Directory, embedding into existing operational workflows rather than requiring teams to learn and maintain a separate process.
Crises Control is used by organisations across the oil and gas sector to manage incidents from first alert to final report. To see how the platform performs against the specific requirements of your operation, request a personalised demo.
FAQs
1. What is crisis management software and why does oil and gas need it?
Crisis management software is a platform that helps organisations prepare for, respond to, and recover from critical incidents. It centralises communication, automates response workflows, assigns tasks to the right teams, and creates a documented audit trail of every action taken. For oil and gas operators, it is the infrastructure that translates an emergency response plan into coordinated action under real pressure – across multiple sites and teams simultaneously. The sector’s combination of remote locations, rotating shift crews, high-hazard processes, and stringent regulatory requirements makes generic communication tools inadequate.
2.What makes crisis management software different for oil and gas compared to other industries?
Oil and gas operations involve remote and offshore environments with limited connectivity, 24/7 shift patterns where named individuals are regularly unavailable, multi-site coordination across jurisdictions, simultaneous regulatory obligations under frameworks including OSHA PSM (29 CFR 1910.119), BSEE offshore regulations, and EPA Risk Management Program requirements, and incidents that can escalate from contained to catastrophic within minutes. Generic crisis management platforms are not built for this combination of constraints. Oil and gas-specific platforms must function on satellite links and roaming networks, handle role-based rather than name-based task assignment, and produce compliance documentation that meets sector-specific regulatory expectations.
3.How does OSHA PSM affect crisis management software requirements?
OSHA’s Process Safety Management standard (29 CFR 1910.119) requires covered facilities to establish and implement emergency action plans, train employees on emergency operations, and conduct compliance audits at least every three years. After any significant incident, the standard requires contemporaneous documentation of what happened and what was done in response. Crisis management software that automatically logs every alert, task assignment, acknowledgement, and escalation with timestamps creates that documentation as a natural byproduct of the response – rather than requiring manual reconstruction after the fact. The platform’s audit trail becomes compliance evidence without additional administrative burden.
4.Why does infrastructure independence matter for oil and gas crisis response software?
The Shamoon cyberattack on Saudi Aramco in August 2012 disabled approximately 30,000 workstations and forced coordination by telephone and fax. The DarkSide ransomware attack on Colonial Pipeline in May 2021 compromised the billing and IT systems that the company would normally use to coordinate its response. In both cases, the crisis response infrastructure shared dependencies with the systems under attack. Crisis management software that runs on independent cloud infrastructure – with data centres separate from corporate IT and operational technology environments – remains operational regardless of what the incident has done to the organisation’s own systems.
5.What is the cost of delayed emergency response in oil and gas
Industry estimates place individual offshore platform losses at over $1 million per day during unplanned shutdown. Aberdeen Group research quantified average unplanned downtime costs for offshore operators at $38 million annually, with the worst performers exceeding $88 million per year. Beyond direct production losses, delayed response to environmental incidents creates regulatory liability, legal exposure, and reputational damage that persists long after the incident itself is resolved – as the Deepwater Horizon case demonstrated, where the 2016 natural resource damage settlement alone reached $8.8 billion.