
Written by Dr Shalen Sehgal | Crises Control
It starts with an alarm.
Could be 2pm on a platform in the North Sea. Could be 3am at a refinery in Texas. A sensor trips. A pressure reading spikes. A worker smells something they should not smell. In the space of seconds, an ordinary operational day becomes a race against time.
What happens next, in those first 10 minutes, is what separates a contained incident from a catastrophe.
And this is where oil and gas emergency response most often fails. Not from lack of plans, not from untrained teams, but from the gap between having a plan and executing it under real pressure, when the clock is already running and the hazard is already moving.
In oil and gas, the first 10 minutes do not test your plan. They test whether your plan actually works when it has to.
Why the First 10 Minutes Matter More Than Anything Else
Oil and gas facilities are not like other workplaces. The hazards move fast and they multiply.
A gas leak does not stay small. A fire in a process module does not wait for the incident commander to be located. Hydrogen sulphide at certain concentrations can incapacitate a person in under a minute. Blowouts, pressure surges, and equipment failures cascade. What is a controlled situation at minute one can be uncontrollable by minute fifteen.
According to the Bureau of Safety and Environmental Enforcement (BSEE), offshore oil rigs experienced 23 explosions and 981 fires between 2014 and 2024, resulting in 25 deaths and 2,161 injuries. IOGP data shows that in 2024, there were 32 fatalities across the global oil and gas industry, with drilling, workover, and well operations accounting for the highest share. The Pipeline and Hazardous Materials Safety Administration logged an average of 1.45 pipeline incidents every single day in 2024.
These are not rare events. They are daily operational realities in one of the world’s most hazardous industries.
And in virtually every post-incident review, the same finding appears: the window for effective intervention is measured in minutes. Miss it, and the trajectory changes.
The first 10 minutes after an oil and gas incident are not the start of the response. They are the response. Everything else is recovery or damage control.
What a Communication Breakdown Actually Looks Like
On 6 July 1988, an alarm sounded on the Piper Alpha platform in the North Sea.
It was not unusual. The condensate pumps tripped regularly. The control room operator said later that his first thought was routine. But this time, the engineers who restarted Pump A did not know that its pressure safety valve had been removed for maintenance earlier that day. The permit for that maintenance work had either been misfiled or was simply not found during the shift handover. Nobody passed that information to the incoming crew. There was no written procedure for shift handovers. The information that mattered most fell through the gap between one team and the next.
Within minutes of the pump restarting, condensate leaked through the temporary blind flange. Gas ignited. The first explosion tore through the control room and destroyed the emergency response infrastructure. A second explosion followed at 10:20pm.
167 people died because information did not move between two shifts. That is not an extreme failure. It is the most common single failure mode in oil and gas emergency response playing out, at lower stakes, across facilities every day.
The pattern is consistent. The National Commission on the BP Deepwater Horizon Oil Spill (2011) described the Macondo disaster as characterised by an environment that lacked both listening and communication. An ill-prepared crew and unclear chain of command prevented critical decisions from being made. The chain of events could have been interrupted at many points. The coordination gap closed each of those windows.
Where Oil and Gas Emergency Response Breaks Down
When safety professionals review what goes wrong in the first 10 minutes of an oil and gas incident, the same failure points appear, across different operators, different geographies, and different incident types.
Here are the six most consistent ones:
- The plan exists on paper, not in practice
- The wrong people get notified first
- Communication fragments across channels
- Nobody owns the next decision
- Leadership loses visibility immediately
- Nothing is documented
Each of these is explored below.
- The plan exists on paper, not in practice
Every facility has an emergency response plan. Most of them sit in a shared drive or a binder. When an alarm sounds at 3am, nobody is opening a PDF to find the right section. Teams improvise. They call the people they know. They use the channels they already have open.
The plan that was never made operational cannot save anyone.
- The wrong people get notified first
Manual call trees are slow. They depend on someone making the right calls in the right sequence under pressure, using contact details that may not be current. In oil and gas, where 24-hour shift patterns mean the person on the call list may have handed over hours ago, this is a consistent failure point. The permit-to-work breakdown at Piper Alpha is the most documented example, but the mechanism, critical information failing to reach the right person at the right moment, appears in post-incident reviews across the industry.
- Communication fragments across channels
Radio. Phone. WhatsApp. Email. The site emergency channel. The company operations centre. During an active incident, information spreads across every channel available, and no single person has the full picture.
Site teams know what is happening on the ground. The operations centre has partial information from the control room. Senior leadership is receiving second-hand updates. Everyone is working from a different version of the same situation.
- Nobody owns the next decision
In the first 10 minutes, the hardest question is not what happened. It is who is responsible for the next action.
If roles are not assigned before the incident, they get assigned in the moment. Under pressure. With incomplete information. By whoever happens to be nearest to the decision. That process is slow and inconsistent, and it means critical actions fall between teams because each assumes the other is handling it.
- Leadership loses visibilityimmediately
In a well-designed response, senior leaders have a live view of the situation from the moment an incident is declared. In most real incidents, they are making phone calls asking for updates.
By the time leadership has enough information to make a decision, the window for that decision may already be closed.
- Nothing is documented
In the first 10 minutes, nobody is writing anything down. Everyone is responding. The decisions made, the instructions given, the sequence of events, all of it exists in people’s memories and scattered message threads.
After an oil and gas incident, the investigation starts. Regulators want a timeline. Insurers want documentation. Legal teams need a record. If the first 10 minutes were managed through informal channels, that record has to be reconstructed from memory. And reconstructions are unreliable.
Interested in our Ping Mass Notification Software?
Efficiently alert everyone in seconds at scale with our Mass Notification Software.
The Modern Operating Environment Makes This Harder
Oil and gas operations in 2025 are more complex than they have ever been.
Offshore platforms operate in increasingly remote locations with satellite-dependent communications. Onshore rigs span multi-site operations across multiple time zones and regulatory jurisdictions. Ground crews, contractors, on-call engineers, and third-party specialists all need to be coordinated during an active incident, often simultaneously, often from different parts of the world.
The Alberta Energy Regulator’s Directive 071 mandates response time commitments depending on hazard zone classification. In practice, reaching the right on-call engineer, mobilising the right contractor, and coordinating with local emergency services consistently runs up against the challenge of manual processes that were not designed for incidents that cascade faster than phone trees can move.
Unplanned downtime in an oil and gas facility can cost an average of $25,000 per hour for mid-sized operations and far more for large ones, according to the 2024 State of Industrial Maintenance Report. Every minute of delayed response compounds that cost.
In 2025, one leaked video of a flare-out or an explosion can reach a global audience within hours. The reputational stakes have never been higher. And the response window has never been shorter.
What Effective Oil and Gas Emergency Response Looks Like
The organisations that manage oil and gas incidents most effectively share specific structural characteristics. These are observable in post-incident reviews across the industry, not aspirational principles.
- The response activates automatically
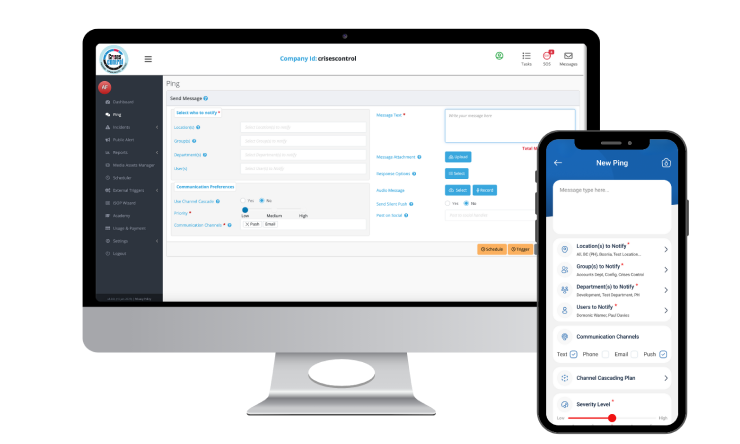
When an incident is detected, predefined workflows trigger immediately. The right teams are notified across the right channels without anyone having to initiate each step manually. A mass notification system that reaches on-call engineers, site managers, HSE leads, and external emergency services simultaneously, in seconds, removes the dependency on manual call trees that have been the most consistent failure point in oil and gas emergency response.
- Roles are assigned before the incident, not during it
Every person in the response chain knows what they are responsible for the moment an incident is declared. Task assignment is built into the workflow, not decided in real time under pressure. This is the structural difference that separates an incident response plan that works from one that looks credible on paper.
- Communication runs through one channel
All critical communications during the incident, alerts, status updates, task confirmations, escalation decisions, flow through a single platform. Every message is visible to everyone with access. Nobody is working from a different version of the situation. The emergency communication system operates independently of the corporate systems that may be affected by the incident itself.
- The audit trail builds itself
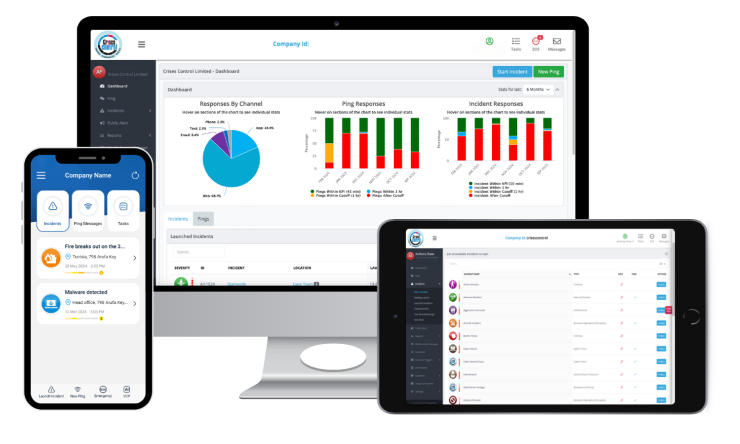
Every alert sent, every task assigned, every acknowledgement received, every escalation made is time-stamped and logged automatically. By the time the incident closes, a complete operational record exists. Not a reconstruction from memory, but a real-time document of what happened and when. This is what regulators, insurers, and legal teams need. Read more about building a crisis management workflow that creates this record as a natural byproduct of the response.
How Crises Control Supports Oil and Gas Emergency Response
This is what that structure looks like in practice, implemented for oil and gas operators running the same response challenges described above.
Crises Control is used by oil and gas operators, including offshore platforms, onshore facilities, and pipeline operators, to close the coordination gap that post-incident reviews consistently identify as the source of the most critical failures.
When an incident is logged, predefined response workflows activate immediately. On-call engineers, HSE leads, site managers, operations centre staff, and external emergency contacts are all reached simultaneously, across SMS, push notification, voice call, and email, through a single platform that operates independently of the infrastructure that may be under pressure.
Tasks are assigned to roles, not individuals, so the response is not disrupted when the named contact is unavailable, on the wrong shift, or out of range. Two-way communication tracks acknowledgement in real time, giving incident commanders a live picture of who has responded and which actions are underway.
The platform creates a complete, automatically generated audit trail throughout the response. Every decision is logged. Every communication is timestamped. When the regulator asks for the timeline of your response, the record already exists. See how incident response automation removes the manual steps that slow down the first minutes of a real emergency. For operations subject to OSHA Process Safety Management requirements, API standards, or regional regulations, that documentation is evidence of compliance. User reviews on the Crises Control Capterra listing highlight speed of notification delivery and ease of use under operational pressure as the capabilities that matter most in a real incident.
The Takeaway
Piper Alpha. Deepwater Horizon. The September 2024 saltwater disposal well explosion in Martin County, Texas. The October 2024 chemical release at the Pemex Deer Park refinery that hospitalised 13 workers.
Different operators, different countries, different years. The same pattern: a communication failure, a coordination gap, a decision that came too late.
In each case, the plan existed. The training had happened. The failure was in the systems that were supposed to translate that plan into coordinated action under real conditions.
That gap is not permanent and it is not inevitable. Organisations that invest in response infrastructure, not just response plans, operate differently when it matters. They reach the right people faster. They maintain a shared picture across all teams. They document as they go. And when the regulator asks what happened and when, the answer already exists.
The first 10 minutes are not a test of capability. They are a test of structure. And structure is something that can be built before the next alarm sounds. Explore the crisis management strategies that oil and gas organisations are using to close this gap right now.
Your next incident will not wait for you to be ready. See how Crises Control helps oil and gas teams activate their response in seconds, coordinate across every site, and document everything automatically. Book a free personalised demo.
Request a FREE Demo
FAQs
1. Why does oil and gas emergency response fail even when plans exist?
Because plans are static, but emergencies are not. A plan outlines what should happen, but what breaks in real conditions is coordination. When the system that connects people, actions, and real-time visibility is manual or fragmented, teams improvise. That is where incidents escalate.
2. What are the most common coordination failures offshore vs onshore?
- Offshore, the main challenge is isolation and limited communication infrastructure. Delays in reaching teams and coordinating with onshore support slow the response.
- Onshore, the issue is fragmentation. Multiple sites, contractors, and regulators operate separately with no shared view.
Different environments, same problem: no unified coordination.
3. What did the Piper Alpha disaster reveal?
The 1988 Piper Alpha disaster, which killed 167 people, exposed a critical communication failure during shift handover. A missing safety valve was not communicated, leading to an explosion.
The key lesson: failures are rarely just human error. They are system failures where critical information does not reach the right people in time.
4. What are oil and gas emergency response best practices?
- Make response plans operational, not just documented
- Notify all relevant teams at the same time across multiple channels
- Assign clear task ownership before incidents occur
- Use one platform for all incident communication
- Automatically log every action for accountability and compliance
5. How does technology improve crisis communication in oil and gas?
Technology removes manual delays. It enables instant multi-channel alerts, real-time shared visibility, and automatic tracking of actions and decisions.
Platforms like Crises Control ensure everyone sees the same situation, responds faster, and maintains a complete audit trail without extra effort.