
Written by Dr Shalen Sehgal | Crises Control
An end-to-end incident coordination platform is the enterprise resilience layer that runs the complete lifecycle of a disruptive event from detection through coordinated response to regulatory audit. For enterprises in regulated industries entering tighter 2026 supervisory cycles under DORA, the UK Cyber Security and Resilience Bill, FCA operational resilience expectations, and equivalent regimes globally, the difference between a fragmented incident response and an end-to-end one is the difference between explaining yourself to a regulator and evidencing yourself to one.
This guide explains what changes at each stage of enterprise resilience maturity, how an end-to-end incident coordination platform supports cross-departmental coordination specifically, and how the same platform serves five regulated industries with different supervisory regimes but identical underlying mechanics. It is written for enterprise resilience directors, chief operating officers, chief risk officers, and the boards that increasingly own operational resilience as a named line of regulatory accountability.
Why operational resilience is a 2026 enterprise priority, not a 2027 nice-to-have
Three converging forces have moved operational resilience from the second line of defence into the boardroom in 2026.
Regulatory scope has expanded. DORA entered application in January 2025, bringing financial entities and their critical ICT third parties into formal operational resilience scope across the EU and indirectly across the UK. The UK Cyber Security and Resilience Bill is at Report Stage with Royal Assent expected in late 2026, extending direct regulatory accountability to managed service providers, designated critical suppliers, data centres, and large load controllers. FCA operational resilience expectations require firms to identify their important business services and set impact tolerances. Sector regulators across healthcare, energy, transport, and water have published equivalent expectations through 2025 and 2026.
Incident scale has increased materially. The UK National Cyber Security Centre managed 204 nationally significant cyber incidents in the past 12 months, more than double the 89 recorded the year before, with 429 cyber incidents in total. The Jaguar Land Rover Category 3 systemic event in 2025 affected over 5,000 UK organisations and caused an estimated £1.9 billion in UK economic impact, mostly through supply chain dependencies. 95% of UK critical national infrastructure organisations experienced a data breach in 2024.
Board-level accountability has formalised. Operational resilience now sits as a named risk category in board reporting frameworks across regulated sectors. Boards are asked to evidence that the enterprise can absorb, respond to, and recover from severe-but-plausible disruption scenarios. The evidence is no longer a plan document filed with the regulator; it is the live operational record of how the enterprise actually behaves during incidents. That shift forces a platform-level conversation that previously sat with departmental managers.
The UK NCSC managed 204 nationally significant cyber incidents in the past 12 months, more than double the 89 recorded the year before. (NCSC Annual Report 2025)
The five stages of enterprise incident coordination maturity
Enterprises do not adopt end-to-end incident coordination platforms in a single jump. They progress through five identifiable stages of maturity, each one defined by a different relationship between the enterprise, its departments, its tooling, and its regulators. Most large enterprises in 2026 sit between stages 2 and 3. Mature regulated-industry enterprises sit at stage 4 or above. The platform-led shift happens between stages 3 and 4, where coordination moves from human-led to platform-orchestrated.
The five stages below each describe what the operational picture looks like, and what an end-to-end incident coordination platform specifically changes when the enterprise adopts it. The transition between stages is not automatic. It requires deliberate programme investment, but the operational and regulatory return is well-evidenced across the regulated-industry deployments referenced in this guide.
|
# |
Stage |
Posture |
Typical evidence at audit |
|
1 |
Fragmented departmental response |
Reactive |
Email threads, retrospective minutes |
|
2 |
Documented plans, manual execution |
Procedural |
Plan documents, exercise reports |
|
3 |
Departmental tools, partial integration |
Coordinated |
Tool-by-tool exports, manually reconciled |
|
4 |
End-to-end platform, orchestrated execution |
Platform-orchestrated |
Live audit trail, on-demand regulator export |
|
5 |
Continuous learning, scenario-validated |
Adaptive
|
Pre-event simulation evidence + live data |
STAGE 1 OF 5 · Reactive
Fragmented departmental response
WHAT THIS LOOKS LIKE Each department handles incidents inside its own toolset. IT runs through ITSM tickets. Finance handles disruption through its risk register. Communications drafts statements in shared documents. Legal works from email. Supply chain calls vendors. Nobody has a single view of an incident that affects three departments. The CEO learns about the incident from a forwarded email forty minutes after it started. The post-incident report is assembled from minutes, screenshots, and best recollection two weeks later.
WHAT THE PLATFORM CHANGES The end-to-end incident coordination platform replaces the multi-tool patchwork with a single major-incident record visible across departments. The IT alert that lands on the ITSM ticket also raises the major incident on the platform; the platform pages communications, finance, and legal automatically when the incident crosses defined thresholds. The CEO learns about the incident within four minutes through the same platform the operational team is already using.
Enterprises at stage 1 typically face their first regulatory finding within twelve to eighteen months of being asked to evidence cross-departmental coordination under a major operational resilience review. The findings are not about the underlying incident handling; they are about the absence of evidence that the handling happened in a coordinated way.
STAGE 2 OF 5 · Procedural
Documented plans, manual execution
WHAT THIS LOOKS LIKE The enterprise has invested in business continuity plans, incident response runbooks, and cross-departmental playbooks. The documents are well-written. They sit in SharePoint, on shared drives, and in printed binders kept in offices nobody visits during an actual incident. When the incident lands at 03:00 on a Sunday, the on-call manager works from memory rather than the plan. The plan is consulted in the post-incident review, mostly to identify where it should be updated.
WHAT THE PLATFORM CHANGES The platform converts static plan documents into live executable workflows. The same content that previously sat in a SharePoint plan now lives as a triggered playbook inside the platform. When the incident lands, the platform raises it, fires the playbook, assigns named owners to each task, and tracks completion in real time. The plan does not need to be remembered, retrieved, or interpreted. It runs.
Plans are designed to be read. Working incident coordination platforms are designed to be run. The two are not interchangeable; they sit at different stages of operational resilience maturity.
STAGE 3 OF 5 · Coordinated
Departmental tools, partial integration
WHAT THIS LOOKS LIKE The enterprise has invested in good tooling per department. ITSM (ServiceNow, Jira Service Management), monitoring (Datadog, Splunk), risk and compliance (Archer, MetricStream), business continuity planning (Riskonnect, Fusion), mass notification (Everbridge, AlertMedia), and crisis communications platforms. Each tool produces useful output. The tools do not talk to each other natively. Cross-tool reconciliation during an incident is a manual exercise carried out by a specific named individual whose calendar is therefore always full.
WHAT THE PLATFORM CHANGES The end-to-end incident coordination platform sits above the existing departmental tools and integrates with all of them bidirectionally rather than replacing them. Alerts from monitoring tools feed in. Tickets from ITSM tools feed in. Risk records update both ways. Mass notification fires from the same platform that runs the workflow. The platform becomes the single authoritative timeline reconciling the partial views that previously lived in each tool. The named individual whose calendar was always full is freed up to do strategic work.
Stage 3 to stage 4 is the platform-led transition. It is the point where most enterprises decide between investing in another departmental tool or investing in the layer above them. The strongest argument for the layer above is regulatory: stage 4 evidence is the only evidence that holds up cleanly under DORA, the CSR Bill, and FCA operational resilience review.
STAGE 4 OF 5 · Platform-orchestrated
End-to-end platform, orchestrated execution
WHAT THIS LOOKS LIKE The enterprise runs incidents through a single end-to-end platform. Detection signals from monitoring, ITSM, security operations, and external feeds correlate into major incident records automatically. The platform pages named owners across SMS, voice, email, push, app, and Microsoft Teams with two-way confirmation. Playbooks trigger. Tasks track. Stakeholder communications draft from templates by audience tier. The audit trail captures every action against a timestamp. The CEO sees a single dashboard. The compliance team exports the regulatory report from the live record.
WHAT THE PLATFORM CHANGES The platform turns operational resilience from a programme of plans into a programme of evidence. Every incident handled at stage 4 generates the artefacts that demonstrate compliance with the regulator’s actual question: not did you have a plan, but did you actually execute against it, in coordinated form, on time, with evidence. The platform is not a feature of operational resilience at this stage. It is the operational record of it.
Mature stage 4 deployments cut response coordination time by 60 to 80% and turn audit-trail reconstruction from a multi-week exercise into a same-day export. (Crises Control deployment data, 2024-2026)
STAGE 5 OF 5 · Adaptive
Continuous learning, scenario-validated
WHAT THIS LOOKS LIKE The enterprise runs regular scenario exercises through the same platform that runs real incidents. The platform captures simulated and real incident data side by side. Post-incident analysis identifies playbook weaknesses, escalation gaps, and decision delays. The next playbook iteration improves on the last. Severe-but-plausible scenarios required by FCA operational resilience and DORA threat-led penetration testing are exercised, evidenced, and tracked over time. The board sees year-on-year improvement in named operational resilience metrics.
WHAT THE PLATFORM CHANGES At stage 5 the platform stops being a response tool and becomes an organisational learning loop. Each incident becomes input to the next playbook iteration. Each exercise generates the same evidence the regulator wants from real incidents. The enterprise’s operational resilience programme becomes adaptive rather than static. Resilience improvements are measurable. Board reporting shifts from plan-completeness metrics to evidence-of-execution metrics.
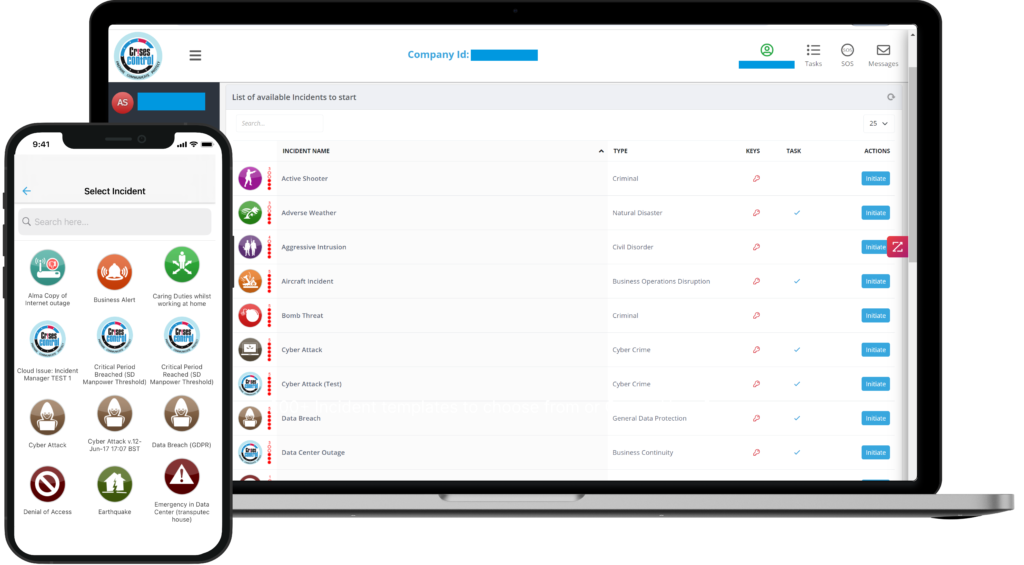
Interested in our Incident Management Software?
Flexible Incident Management Software to keep you connected and in control.
How enterprises manage critical incidents across multiple departments
The defining feature of an enterprise incident is that it crosses departments. Single-department incidents are operational events, handled inside one team’s existing tooling. Cross-departmental incidents are the ones that produce regulatory findings, brand damage, financial loss, and board scrutiny. An end-to-end incident coordination platform is built around the cross-departmental shape.
Six departments typically engage during a major enterprise incident, each with different objectives, different timing requirements, and different communication audiences. The end-to-end platform coordinates all six without forcing any of them out of the tools they already use.
|
Department |
Objective during a major incident |
Platform role |
|
IT / Technology |
Diagnose, contain, recover the technical fault |
Bidirectional ITSM integration; correlated alerting feeds; technical task tracking |
|
Operations |
Maintain continuity of important business services |
Service-impact tracking; resource reallocation tasks; recovery sequencing |
|
Communications |
Inform customers, regulators, media, staff with one voice |
Pre-built templates by audience tier; multi-channel delivery with confirmation |
|
Legal & Compliance |
Manage regulatory notification, disclosure, evidence preservation |
Regulator-format report templates; timestamped audit trail; subject access workflow |
|
Finance / Risk |
Quantify exposure, manage capital impact, brief audit committee |
Impact tolerance tracking; cost capture against incident record; board reporting export |
|
HR & Safety |
Protect employee welfare, manage workforce communication |
Shift-aware routing; welfare check workflows; staff notification by location and role |
The end-to-end platform handles all six departments inside the same major incident record. Each department sees its own tasks, owns its own communications, and contributes to the same audit trail. Nobody has to leave their preferred toolset; the platform integrates upstream into the tools each department already uses. The CEO and the audit committee see one consolidated dashboard rather than six departmental updates that need to be reconciled.
Operational resilience technology for regulated industries: five sector applications
An end-to-end incident coordination platform serves regulated industries with broadly similar underlying mechanics but different regulatory framings. The five sector views below cover the regimes most commonly named in 2026 enterprise procurement reviews.
Financial services: DORA and FCA operational resilience
The Digital Operational Resilience Act (DORA) entered application in January 2025, bringing financial entities (banks, insurers, investment firms, pension funds, crypto-asset service providers) and their critical ICT third parties into formal scope. Threat-led penetration testing, ICT third-party risk management, and incident reporting are all named obligations. The UK FCA operational resilience framework requires firms to identify important business services, set impact tolerances, and evidence the ability to remain within tolerance during severe-but-plausible disruption scenarios.
Financial-services enterprises use end-to-end incident coordination platforms to evidence impact-tolerance compliance during incidents, generate DORA-format incident reports inside the regulatory timing windows, coordinate across treasury, technology, risk, and compliance functions during market-hours disruption, and run severe-but-plausible scenario exercises that feed into the same platform that runs real incidents. The platform becomes the FCA’s evidence layer that the firm executed against its plan, not just had one.
Healthcare: NHS national patient safety alerts and integrated care
Healthcare enterprises in the UK operate under National Patient Safety Alerts, the NHS Patient Safety Strategy, Care Quality Commission oversight, and emerging integrated-care-board level operational requirements. Major incidents in healthcare frequently span clinical, operational, IT, estates, and communications functions simultaneously, often across multiple sites within an integrated care system.
Healthcare enterprises use end-to-end incident coordination platforms to coordinate response across multiple hospital sites under a single ICS-level incident record, deliver shift-aware alerts to clinical and operational staff working different rotas, capture the patient-safety audit trail that CQC and the NHS Patient Safety team review, and run major incident exercises that satisfy emergency preparedness, resilience and response requirements. The platform integrates with electronic patient record systems, building management systems, and clinical communications platforms upstream.
Energy and utilities: NIS Regulations and Ofgem operational resilience
Energy and utilities enterprises operate under the UK NIS Regulations 2018, the upcoming CSR Bill (which expands the NIS regime significantly), Ofgem operational resilience requirements, and the EU Critical Entities Resilience Directive (CER) for cross-border operators. Operators of essential services in this sector face dual notification requirements and named penalty exposure for both cyber and physical incidents.
Energy and utilities enterprises use end-to-end incident coordination platforms to coordinate response across SCADA, OT, IT, field operations, and customer communications during incidents that frequently combine cyber and physical elements, generate dual notifications to sector regulator and NCSC inside CSR Bill timing windows, capture the operational continuity audit trail required by Ofgem operational resilience, and coordinate with mutual-aid partners during sector-wide events. The platform integrates with SCADA monitoring and operational technology systems alongside conventional IT stacks.
Government and public sector: GovAssure and accountability frameworks
Central government departments, executive agencies, and arm’s length bodies operate under the UK Government Functional Standard 7 (GovS 007), GovAssure cyber resilience reviews, the National Audit Office’s operational resilience expectations, and increasingly under the Cabinet Office Resilience Framework. Public-sector incidents combine political accountability, parliamentary scrutiny, and FOI-evidenced timelines with operational pressure.
Government enterprises use end-to-end incident coordination platforms to coordinate cross-departmental response under named ministerial accountability, generate the GovAssure-format evidence that NCSC review during cyber resilience assessments, capture the timeline that withstands National Audit Office and Public Accounts Committee scrutiny, and coordinate across departmental and arm’s-length body boundaries during cross-cutting incidents. The platform produces the audit trail that supports both parliamentary written answers and operational lessons learned.
Manufacturing and supply chain: NIS Regulations and BRCGS
Critical manufacturing enterprises (food, pharmaceuticals, chemicals, defence) operate under NIS Regulations where applicable, the upcoming CSR Bill, sector-specific standards such as BRCGS Global Standard for Food Safety Issue 9 and ISO 22301 business continuity, and increasingly under retailer technical-team operational resilience requirements that are now embedded in supply contracts.
Manufacturing enterprises use end-to-end incident coordination platforms to coordinate response across production, quality, technical, supply chain, customer communications, and regulatory functions during contamination, supply chain disruption, or operational continuity events. The platform delivers the BRCGS Issue 9 incident, withdrawal, and recall audit trail required at certification cycles, coordinates retailer technical-team notification inside contractual timing windows, and supports the rapid root-cause documentation that ISO 22301 audits review. The platform integrates with quality management, ERP, and supply chain visibility tools.
What a stage 4 enterprise resilience programme looks like in practice
Enterprises operating at stage 4 share six observable characteristics. None of them require the platform to be the only investment in operational resilience; all of them require the platform to be the layer where the rest of the programme is operationalised.
First, a single major incident record per incident across all departments. The IT alert, the operations task list, the legal hold, the communications message log, and the finance impact assessment all reconcile to the same record. No two departments are working from different versions of the truth.
Second, multi-channel notification with confirmation, routed by role and shift. SMS, voice, email, push, app, Microsoft Teams or Slack, all delivered in parallel with two-way acknowledgement. Critical-alert frameworks reach on-call staff at 03:00 on a Sunday. Deputies are named. Escalation is automatic.
Third, playbook-driven workflow with named owner accountability. Pre-built playbooks for incident types ship with the platform and are customised to the enterprise’s specific operating model. When the incident is raised, the playbook runs. Tasks are owned by named individuals. Status is tracked. Nobody starts the workflow because the workflow has already started.
Fourth, bidirectional integration with departmental tooling. ITSM, monitoring, identity, HR, communications, ERP, and risk-and-compliance systems all feed into and update from the platform. The departments do not abandon their tools; they coordinate through the platform layer above.
Fifth, regulator-format reporting on demand. DORA reports for financial services. CSR Bill 24-hour and 72-hour reports. CQC patient safety reports for healthcare. GovAssure evidence for government. BRCGS recall audit trails for manufacturing. The templates exist inside the platform, populated from the live record, exportable in minutes.
Sixth, continuous audit trail aligned to ISO 22301 and ISO 27001. Every alert, acknowledgement, decision, task, and notification captured automatically against second-level timestamps. Tamper-evident. Exportable in PDF, CSV, JSON, and regulator-format templates. The trail satisfies internal audit, external assurance, regulatory review, and post-incident learning in a single artefact.
How Crises Control delivers an end-to-end incident coordination platform for enterprises
Crises Control is the end-to-end incident coordination platform purpose-built for enterprises operating in regulated industries under tightening operational resilience scrutiny. The platform itself holds ISO 22301 and ISO 27001 accreditation. The standards are built into the product rather than configured on top.
Single major-incident record across six departments
The Crises Control Incident Manager creates a single major-incident record that IT, operations, communications, legal, finance, and HR all contribute to simultaneously. Each department sees the tasks it owns. The CEO sees the consolidated picture. The audit committee sees the evidence on demand.
Multi-channel notification with confirmation
The Crises Control mass notification system reaches employees, contractors, third-party vendors, regulators, and customer-facing channels across SMS, voice, email, push, app, and Microsoft Teams in parallel with two-way confirmation and automatic escalation to named deputies. Shift-aware routing reaches the right named owner on the right channel at the right time of day.
Pre-built playbooks for regulated-industry scenarios
Over 200 pre-built playbook templates ship with the platform, covering cyber incidents, supply chain failures, data breaches, business continuity activation, regulatory notifications, severe-but-plausible scenarios, and the sector-specific scenarios required by DORA, FCA operational resilience, NIS Regulations, BRCGS Issue 9, and equivalent regimes. Customisable through a no-code editor by the enterprise’s own resilience team.
Bidirectional integration with enterprise tooling
Native integration with ServiceNow, Jira Service Management, Microsoft Teams, Slack, SAP, Workday, Azure AD, Okta, and the major monitoring stacks. SAML SSO and SCIM provisioning out of the box. The Crises Control Task Manager coordinates the parallel workstreams without forcing any department off its preferred operational tool.
Regulator-format reporting and continuous audit trail
CSR Bill 24-hour and 72-hour reports, DORA incident reports, FCA operational resilience evidence packs, CQC patient safety reports, BRCGS Issue 9 recall audit trails, and ISO 22301 evidence exports all generated from the live major-incident record. The Crises Control audit and reporting module captures every action automatically against second-level timestamps with tamper-evident hashing.
Move your enterprise from stage 2 or 3 to stage 4 in the 2026 regulatory cycle. The platform that runs the response is the platform that evidences the response. Book a Crises Control demo.
FAQs
1. What is an end-to-end incident coordination platform in enterprise terms?
An end-to-end incident coordination platform is the enterprise resilience layer that runs the complete lifecycle of a disruptive event from detection through coordinated cross-departmental response to regulatory audit. It sits above existing departmental tooling (ITSM, monitoring, risk, communications, ERP) and coordinates across them rather than replacing them. The defining feature is that it handles a single major incident record across IT, operations, communications, legal, finance, and HR simultaneously, with audit-grade evidence captured automatically.
2. How do enterprises improve operational resilience using an incident coordination platform?
Enterprises improve operational resilience by progressing from stage 1 (fragmented departmental response) through stage 5 (continuous learning, scenario-validated) on the maturity ladder described in this guide. The platform is the operational enabler of the stage 3 to stage 4 transition, where coordination moves from human-led to platform-orchestrated. Mature stage 4 deployments cut response coordination time by 60 to 80% and turn audit-trail reconstruction from a multi-week exercise into a same-day export. Stage 5 adds adaptive learning through scenario exercise integration.
3. How does an end-to-end incident coordination platform support DORA and FCA operational resilience?
The platform generates DORA-format incident reports inside regulatory timing windows from the live incident record, evidences FCA impact-tolerance compliance during real incidents, supports severe-but-plausible scenario exercise capture, and runs threat-led penetration testing post-event analysis through the same audit trail used for real incidents. The platform is the operational evidence layer that satisfies the regulator’s actual question: not did you have a plan, but did you execute against it in coordinated form, on time, with timestamped audit-grade evidence.
4. Does an end-to-end incident coordination platform replace ITSM, business continuity planning, or mass notification tools?
No. The platform sits above existing departmental tooling and coordinates across them bidirectionally. ITSM continues to handle the technical ticket lifecycle. Business continuity planning tools continue to maintain the plan documents. Mass notification platforms continue to deliver alerts. The end-to-end platform is the layer where all of these tools contribute to a single major-incident record and a single audit trail. The strongest deployments retain departmental tooling investments and add the coordination layer above them.
5. How long does it take an enterprise to move from stage 3 to stage 4 on the maturity ladder?
Typical enterprise deployments achieve operational stage 4 within four to nine months from platform contract signature. The variability is driven by integration complexity, departmental change management, and pre-existing playbook maturity, not by the underlying technology. Financial services enterprises with complex existing tooling typically take six to nine months. Healthcare and government enterprises with strong existing playbook libraries typically deploy in four to six months. Manufacturing enterprises with well-defined sector regulatory requirements typically deploy in three to five months